Пост 13. Начинаем работу!
Итак, пора уже наконец начать работу с Oracle NoSQL DB
Для этого надо скачать виртуалку.
Для этого надо скачать виртуалку.
К сожалению, в силу лицензионной политики моей компании я не могу выкладывать виртуальные машины в открытый доступ. Поэтому пишите на e-mail: а oracle.nosql@gmail.com, я вышлю инструкции, где будет сказано о том,как ее получить.
После скачивания, собираем(разбивал total commander), запускаем (VmWare), читаем инструкцию и наслаждаемся NoSQL DB!
1) Работу следует начать с переразвертывания базы. Запускаем скрипт
/opt/oracle/ReDeploy.sh
2) Далее запускает IDE NetBeans (ярлык на рабочем столе)
3) Описание пакетов
- Support
Вспомогательный пакет. Содержит 2 класса.
Support.OraStore.java - класс содержит 1 метод, используется для подключения к базе.
На вход подаем имя хранилища, получаем указательна объект БД.
Support.ParseKey.java - класс содержит 1 метод, осуществляет разбор ключа по заданному шаблону.
На вход подается String - отдается указатель на объект типа Key.
пример входных данных: major1/major2/-/minor1 (заметье, major1/major2/-/minor1 - НЕ ВЕРНО )
- CRUD
Пакет, включающий в себя классы, выполняющие CRUD (Create Retrieve Update Delete) операции.
Create. Этот класс предназначен для создание пар ключ-значение в базе. Содержит 3 метода с одинаковыми конструторами.
- putIfPresent - метод записывает пару ключ-значение,если данные есть, если данныех нет - выкидывает exeption.
- putIfAbsent - метод записывает пару ключ-значение,если данных нет, если данные есть - выкидывает exeption.
- put - записыавет пару ключ-значение в любом случае.
Конструктор (String sKey, String data, KVStore myStore).
sKey - ключ в формате строки (внутри метода происходит парсинг).
пример: major1/major2/-/minor1.
data - значение. Данный метод поддерживает только value типа String.
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
Retrieve. Этот класс предназначен для извлечения пар ключ-значение из базы.
- SelectRow - метод для извлечения одной стороки.
Конструктор(String sKey, KVStore myStore), возвращает String.
sKey - ключ в формате строки (внутри метода происходит парсинг).
пример: major1/major2/-/minor1.
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
- SelectAll - метод для извлечения всей базы данных (вывод на экран).
Конструктор(KVStore myStore).
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
- SelectWhereFullMajor - метод для извлечения множества строк по ПОЛНОМУ major ключу (вывод на экран)
Конструктор(String sKey, KVStore myStore)
sKey - major составляющая ключа
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
Пример: есть ключи
major1/major2/-/minor1/
major1/major2/-/minor2/
major1/major2/-/minor3/
Их все надо извлечь.
задать в качестве ключа (sKey) необходимо "major1/major2/"
НЕЛЬЗЯ искать по части: "major1"
- SelectWhere - метод для извлечения множества строк по ЧАСТИ major ключа (вывод на экран)
Конструктор(String sKey, KVStore myStore)
sKey - major составляющая ключа
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
Пример: есть ключи
major1/major2/-/minor1/
major1/major3/-/minor2/
major1/major4/-/minor3/
Их все надо извлечь.
задать в качестве ключа (sKey) необходимо "major1/"
Но метод не работает с полными major ключами
Update. Класс содержит 1 метод: putIfpresent (описание см. выше в классе Create).
Delete. Класс содержит 2 метода.
- ClearStore. Удаление всех данных из базы.
Конструктор(KVStore myStore).
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
- DeleteKey. Удаление одной пары из базы.
Конструктор(String sKey, KVStore myStore), возвращает String.
sKey - ключ в формате строки (внутри метода происходит парсинг).
пример: major1/major2/-/minor1.
myStore - объект базы даных. Указатель на объект дожен быть создан ранее.
- SocialNetwork
Пакет непосредственно реализующий приложение (как раз таки использует пакеты CRUD и Support). В данном случае - некая соц. сеть
Auth - класс для администрирования и аутентицикации пользователей
- add_admin метод для добавления пользователей
Конструктор(String AdminName, String AdminAtribute, String Pass, KVStore myStore)
AdminName - имя нового пользователя
AdminAtribute - атрибуты нового пользователя (возраст, пол, образование ... )
Pass - пароль нового пользователя
myStore - указатель на объект базы данных (необходимо создать ранее, методу передается лишь указатель)
- check_passwd - аутентификация пользователя. Возвращает String "Yes" или "No"
Конструктор (String AdminName, String AdminPass, KVStore myStore)
AdminName - имя пользователя (логин)
Pass - пароль пользователя
myStore - указатель на объект базы данных (необходимо создать ранее, методу передается лишь указатель)
MessageManagment - класс для управления потоком собщений соц. сети.
- post данный метод осуществляет пост сообщения на стену
Конструктор (String UserName, String text, KVStore myStore)
UserName - пользователь, оставляющий сообщение
text - текст сообщения
myStore - указатель на объект базы данных (необходимо создать ранее, методу передается лишь указатель)
- subscribe_to подписка на сообщения другого пользователя
Конструктор (String User, String IntrestingPerson, KVStore myStore)
User - тот кто подписывается
IntrestingPerson - тот на кого подписываются
myStore - указатель на объект базы данных (необходимо создать ранее, методу передается лишь указатель)
- show_tape метод, отображающий стену (ТОР N сообщений, пользователя и того на кого он подписан, отсортированных по времени)
Конструктор (String User, int tape_depth, KVStore myStore)
User пользователь, чью стену необходимо отрисовать
tape_depth - колличество сообщений которые надо отображать (ТОР N)
myStore - указатель на объект базы данных (необходимо создать ранее, методу передается лишь указатель)
SocialNetwork - main класс проекта.
Если будут вопросы - не стесняйтесь их задавать!
вторник, 25 сентября 2012 г.
пятница, 17 августа 2012 г.
Пост 12. ACID. Durability.
Едем дальше. Durability. Что это значит? А значит это то, что независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу. Другими словами если пользователь внес данные в вашу систему и почил подтверждение о том, что они успешно записаны, они не должны быть потеряны, вне зависимости ни отчего (пропало питание в ЦОД, посыпался диск...). Ну представьте вы купили электронный авиабилет, вам пришло подтверждение. Тут же посыплся диск на который вы записали свои данные. Приезжаете в аэропорт в солнцезащитных очках, гавайской рубашке и в предвкушении долгожданного пляжного отдыха, а Вам говорят, что данных в системе нет. Ситуация конечно излишне гиперболизирована, но суть думаю ясна.
В контексте Oracle NoSQL это выглядит вот так:
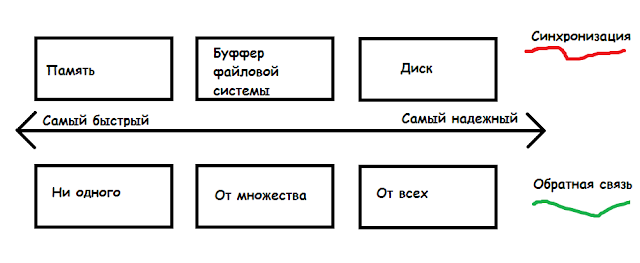
Рис.1. Durability.
Итак, при проектировании приложения нам приходится выбирать между надежностью и скоростью. У нас есть 2 измерения для выбора "золотой середины". Первое - уровень синхронизации - когда данные могут считаться записанными: когда они попали в ОЗУ (самое быстрое), когда из ОЗУ они перешли в буфферный кэш файловой системы, либо когда они попали на диск (самое надежное). Второе измерение это так называемая обратная связь (сколько серверов подтвердило поступление пары ключ-значение). Самое быстрое - "ни одного", то есть пары попали только на мастера, далее следует режим majority (от многих), ну и самым надежным является тот случай, если получение пары подтвердили все сервера репликационной группы. Использовать это API проще простого.
Устанавливаем настройки надежности:
Durability durability =
new Durability (Durability.SyncPolicy.SYNC, Durability.SyncPolicy.SYNC, Durability.ReplicaAckPolicy.ALL);
myStore.put(myKey, myValue,null,durability,30, TimeUnit.SECONDS);
Вот как то так.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Едем дальше. Durability. Что это значит? А значит это то, что независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу. Другими словами если пользователь внес данные в вашу систему и почил подтверждение о том, что они успешно записаны, они не должны быть потеряны, вне зависимости ни отчего (пропало питание в ЦОД, посыпался диск...). Ну представьте вы купили электронный авиабилет, вам пришло подтверждение. Тут же посыплся диск на который вы записали свои данные. Приезжаете в аэропорт в солнцезащитных очках, гавайской рубашке и в предвкушении долгожданного пляжного отдыха, а Вам говорят, что данных в системе нет. Ситуация конечно излишне гиперболизирована, но суть думаю ясна.
В контексте Oracle NoSQL это выглядит вот так:

Рис.1. Durability.
Итак, при проектировании приложения нам приходится выбирать между надежностью и скоростью. У нас есть 2 измерения для выбора "золотой середины". Первое - уровень синхронизации - когда данные могут считаться записанными: когда они попали в ОЗУ (самое быстрое), когда из ОЗУ они перешли в буфферный кэш файловой системы, либо когда они попали на диск (самое надежное). Второе измерение это так называемая обратная связь (сколько серверов подтвердило поступление пары ключ-значение). Самое быстрое - "ни одного", то есть пары попали только на мастера, далее следует режим majority (от многих), ну и самым надежным является тот случай, если получение пары подтвердили все сервера репликационной группы. Использовать это API проще простого.
Устанавливаем настройки надежности:
Durability durability =
new Durability (Durability.SyncPolicy.SYNC, Durability.SyncPolicy.SYNC, Durability.ReplicaAckPolicy.ALL);
myStore.put(myKey, myValue,null,durability,30, TimeUnit.SECONDS);
Вот как то так.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
среда, 8 августа 2012 г.
Пост 11. ACID. Consistency.

Рис.1 Система находится в согласованном состоянии

Рис.2 Система находится в не согласованном состоянии

Рис.2 Система находится в не согласованном состоянии
А что же мне делать, если я хочу обеспечить выполнене принципа согласованности? И как сказали бы в рекламе Oracle NoSQL летит к Вам!
В начале хотел бы рассказать о том, что такое согласованность в контексте Oracle NoSQL.
Существует несколько типов согласованности (расположены в порядки убывания скорости):
- Согласованность отсутствует (самое быстрое чтение)
- Согласованность по времени
- Согласованность по версии
- Абсолютная согласованность (самое медленное чтение)
Если вы хотите обеспечить согласованное чтение, используйте другой конструктор получения value (get, MultiGet...)
Давайте создадим программу, которая читает одно значение по ключу (аналогичный метод создавался ранее, но в этот раз использовался другой конструктор get)
public static String ConsistencyRead(String sKey, String store, String host, String port) {
OraStore orastore = new OraStore(store, host, port);
String data = null;
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
Key myKey = ParseKey.ParseKey(sKey);
try {
ValueVersion vv = myStore.get(myKey, Consistency.ABSOLUTE, 0, null);
Value v = vv.getValue();
data = new String(v.getValue());
System.out.println(myKey + " : " + data);
} catch (RequestTimeoutException re) {
System.out.println(re.getTimeoutMs());
} catch (FaultException fe) {
System.out.println("Unknown error");
} catch (NullPointerException ne) {
System.out.println("Key does not exist");
} finally {
myStore.close();
System.out.println("Store Closed");
}
return data;
}
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com
понедельник, 6 августа 2012 г.
Пост 10. ACID. Atomicity.
Итак, сейчас хотел бы рассказать про принцип атомарности. Атомарность гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной. Итак, все привыкли думать, что NoSQL базы данных это исключительно BASE системы. "Быстрые, но не надежные". Это не так. Oracle NoSQL может соответствовать ACID концепции. Atomicity в данном контексте это будет просто обозначать транзакции. Долго думал как об этом лучше рассказать - решил добавить еще один класс,с исчерпывающими комментариями, в пакет simpleoperation (о нем читай ниже). Надеюсь все понятно :) Если нет - не стеснятесь задавать вопосы в комментариях или писать по адресу oracle.nosql@gmail.com
package simpleoperation;
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.TimeUnit;
import oracle.kv.*;
public class ACID {
// Прописываем переменные идентифицирующие базу данных
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String args[])
{
import java.util.Iterator;
import java.util.List;
import java.util.concurrent.TimeUnit;
import oracle.kv.*;
public class ACID {
// Прописываем переменные идентифицирующие базу данных
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String args[])
{
// Открываем нашу базу
OraStore orastore = new OraStore(store,host,port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
OraStore orastore = new OraStore(store,host,port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
// Создаем 2 ключа
Key myKey2 = ParseKey.ParseKey(Key2);
// Создаем 2 значения
String data1 = "First value";
String data2 = "Second value";
String Key1 = "key/-/1/";
String Key2 = "key/-/2";
Key myKey1 = ParseKey.ParseKey(Key1);Key myKey2 = ParseKey.ParseKey(Key2);
// Создаем 2 значения
String data1 = "First value";
String data2 = "Second value";
Value MyValue1 = Value.createValue(data1.getBytes());
Value MyValue2 = Value.createValue(data2.getBytes());
// Создание транзакции начинается с создания объекта OperationFactory.
OperationFactory of = myStore.getOperationFactory();
Value MyValue2 = Value.createValue(data2.getBytes());
// Создание транзакции начинается с создания объекта OperationFactory.
OperationFactory of = myStore.getOperationFactory();
// Создаем массив под храниение списка наших операций
List<Operation> opList = new ArrayList<>();
List<Operation> opList = new ArrayList<>();
// Заполняем его операциями объекта of
opList.add(of.createPutIfAbsent(myKey1, MyValue1));
opList.add(of.createPutIfAbsent(myKey2, MyValue2));
System.out.println("Transaction Created");
try
{
opList.add(of.createPutIfAbsent(myKey1, MyValue1));
opList.add(of.createPutIfAbsent(myKey2, MyValue2));
System.out.println("Transaction Created");
try
{
// Запускаем транзакцию
myStore.execute(opList);
System.out.println("Transaction Executed");
}
catch (OperationExecutionException oee)
{
System.out.println("Operation Execution Exception occured " + oee.getMessage());
}
catch (IllegalArgumentException iae)
{
System.out.println("Illegal Argument Exception occured " + iae.getMessage());
}
catch (FaultException fe)
{
System.out.println("Fault Exception occured " + fe.getMessage());
}
}
myStore.execute(opList);
System.out.println("Transaction Executed");
}
catch (OperationExecutionException oee)
{
System.out.println("Operation Execution Exception occured " + oee.getMessage());
}
catch (IllegalArgumentException iae)
{
System.out.println("Illegal Argument Exception occured " + iae.getMessage());
}
catch (FaultException fe)
{
System.out.println("Fault Exception occured " + fe.getMessage());
}
}
}
В итоге будут выполнены 2 операции, либо не выполнена ни одна.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com
четверг, 19 июля 2012 г.
Пост 9. ACID.
Доброго времени суток!
Итак продолжаю свое повествование об Oracle NoSQL Database. Сегодня хотел бы рассказать о таких понятиях, как ACID и BASE. Итак, начнем с ACID, я уверен, что большинство знает, что это такое, но все же хотел бы повториться.
Atomicity — Атомарность
Атомарность гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной.
Представьте себе простейшую банковскую операцию в которой деньги с одного счета преводятся на другой. Это мининум 2 операции БД - снять деньги с одного счета и пополнить другой. Не камильфо будет если с одного счета будут сняты деньги, а на счет 2 не поступят. Принцип атомарности в этом случае не будет выпонен.
Consistency — Согласованность
Система находится в согласованном состоянии до начала транзакции и должна остаться в согласованном состоянии после завершения транзакции.
Представьте, что у Вас есть система, состоящая их 2х и более узлов, которые реплицируют одну и туже информацию (попросту говоря копируют). Представьте себе, что вы записали некоторые данные на сервер1 и получили подтверждение успешной записи. Практически в тот же момент другой пользователь запросил данные, которые вы только что записали и не получил их... потому что балансировщик отправил его на сервер2 (куда данные еще не успели среплицироваться). Требование согласованности не выполнено.
Isolation — Изолированность
Во время выполнения транзакции другие процессы не должны видеть данные в промежуточном состоянии.
Durability — Долговечность
Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу.
Другими словами если пользователь внес данные в вашу систему и почил подтверждение о том, что они успешно записаны, они не должны быть потеряны, вне зависимости ни отчего (пропало питание в ЦОД, посыпался диск...).
В противовес концепции ACID стоит концепция BASE.
BASE - Basically Available, Soft state, Eventual consistency
NoSQL DB - система хамелеон, в зависимости от Ваших пожеланий она может с разной степенью поддерживать любую концепцию парадигмы ACID. Как?
Об этом читайте в последующих постах!
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com
Доброго времени суток!
Итак продолжаю свое повествование об Oracle NoSQL Database. Сегодня хотел бы рассказать о таких понятиях, как ACID и BASE. Итак, начнем с ACID, я уверен, что большинство знает, что это такое, но все же хотел бы повториться.
Atomicity — Атомарность
Атомарность гарантирует, что никакая транзакция не будет зафиксирована в системе частично. Будут либо выполнены все её подоперации, либо не выполнено ни одной.
Представьте себе простейшую банковскую операцию в которой деньги с одного счета преводятся на другой. Это мининум 2 операции БД - снять деньги с одного счета и пополнить другой. Не камильфо будет если с одного счета будут сняты деньги, а на счет 2 не поступят. Принцип атомарности в этом случае не будет выпонен.
Consistency — Согласованность
Система находится в согласованном состоянии до начала транзакции и должна остаться в согласованном состоянии после завершения транзакции.
Представьте, что у Вас есть система, состоящая их 2х и более узлов, которые реплицируют одну и туже информацию (попросту говоря копируют). Представьте себе, что вы записали некоторые данные на сервер1 и получили подтверждение успешной записи. Практически в тот же момент другой пользователь запросил данные, которые вы только что записали и не получил их... потому что балансировщик отправил его на сервер2 (куда данные еще не успели среплицироваться). Требование согласованности не выполнено.
Isolation — Изолированность
Во время выполнения транзакции другие процессы не должны видеть данные в промежуточном состоянии.
Durability — Долговечность
Независимо от проблем на нижних уровнях (к примеру, обесточивание системы или сбои в оборудовании) изменения, сделанные успешно завершённой транзакцией, должны остаться сохранёнными после возвращения системы в работу.
Другими словами если пользователь внес данные в вашу систему и почил подтверждение о том, что они успешно записаны, они не должны быть потеряны, вне зависимости ни отчего (пропало питание в ЦОД, посыпался диск...).
В противовес концепции ACID стоит концепция BASE.
BASE - Basically Available, Soft state, Eventual consistency
Базовая
доступность, неустойчивое состояние, согласованность в конечном счёте
- в
принципе доступна
- в
принципе знаем состояние
-
когда-нибудь сойдется
NoSQL DB - система хамелеон, в зависимости от Ваших пожеланий она может с разной степенью поддерживать любую концепцию парадигмы ACID. Как?
Об этом читайте в последующих постах!
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com
Пост 8. CRUD. Delete.
Итак, едем дальше. Создавать записи мы уже умеем. Умеем вытаскивать записи и умеем иъ изменять. Осталось только научиться удалять. Тут все предельно просто.
public static void DeleteKey(String sKey, String store, String host, String port) {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
Key myKey = ParseKey.ParseKey(sKey);
myStore.delete(myKey);
myStore.close();
System.out.println("Store Closed");
}
Собственно, добавить мне нечего. От "скуки" я даже немного изменил концепцию - добавив коннект к базе кнутрь метода :) .
Ну и дабы разбавить этот достаточно неинтересный пост (будем объективны), привожу метод, который удаляет всю Вашу базу - очень удобно для разработки.
public static void ClearStore(String store, String host, String port) {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
System.out.println("Cleaning Store ...");
Iterator<Key> keyIter = myStore.storeKeysIterator(Direction.UNORDERED, 0, null, null, null);
Key key = null;
List<String> majorPath = null;
String majorPathStr = null;
Hashtable<String, String> majorKeyHash = new Hashtable<String, String>();
Integer count = 0;
while (keyIter.hasNext()) {
key = keyIter.next();
majorPath = key.getMajorPath();
majorPathStr = majorPath.toString();
if (!majorKeyHash.containsKey(majorPathStr)) {
majorKeyHash.put(majorPathStr, majorPathStr);
Key newkey = Key.createKey(majorPath);
myStore.multiDelete(newkey, null, null);
System.out.println(++count + " " + majorPathStr);
}
} //EOF while
System.out.println("\nKVStore cleaned.");
myStore.close();
System.out.println("Store Closed");
}
На сегодня наверное все.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Итак, едем дальше. Создавать записи мы уже умеем. Умеем вытаскивать записи и умеем иъ изменять. Осталось только научиться удалять. Тут все предельно просто.
public static void DeleteKey(String sKey, String store, String host, String port) {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
Key myKey = ParseKey.ParseKey(sKey);
myStore.delete(myKey);
myStore.close();
System.out.println("Store Closed");
}
Собственно, добавить мне нечего. От "скуки" я даже немного изменил концепцию - добавив коннект к базе кнутрь метода :) .
Ну и дабы разбавить этот достаточно неинтересный пост (будем объективны), привожу метод, который удаляет всю Вашу базу - очень удобно для разработки.
public static void ClearStore(String store, String host, String port) {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
System.out.println("Store Opened");
System.out.println("Cleaning Store ...");
Iterator<Key> keyIter = myStore.storeKeysIterator(Direction.UNORDERED, 0, null, null, null);
Key key = null;
List<String> majorPath = null;
String majorPathStr = null;
Hashtable<String, String> majorKeyHash = new Hashtable<String, String>();
Integer count = 0;
while (keyIter.hasNext()) {
key = keyIter.next();
majorPath = key.getMajorPath();
majorPathStr = majorPath.toString();
if (!majorKeyHash.containsKey(majorPathStr)) {
majorKeyHash.put(majorPathStr, majorPathStr);
Key newkey = Key.createKey(majorPath);
myStore.multiDelete(newkey, null, null);
System.out.println(++count + " " + majorPathStr);
}
} //EOF while
System.out.println("\nKVStore cleaned.");
myStore.close();
System.out.println("Store Closed");
}
На сегодня наверное все.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
суббота, 9 июня 2012 г.
Статья 7. CRUD. Retrieve part2.
Доброго времени суток!
В прошлом посте я рассказал о том как извлекать одну запись из NoSQL базы. В случае одной записи все проще простого. А как быть если я хочу вытащить несколько записей? Как сказал бы анатолий Кашперовский, если хочешь вытащить несколько записаей - просто возьми их:)
Итак, перед тем как я буду описывать конкретные реализации инструментов извлечения, хотелось бы рассказать о концепции мультиселекта. Вытаскивать можно ключи с различной вложеностью (можно вытаскивать ключ и его детей, внуков итп...) слева на право, но не наоборот (правила как в прямом префиксном индексе).
Например дано:
major1/major2/-/minor1/
major1/major3/-/minor1/
major1/major4/-/minor1/
major2/major2/-/minor1/
Можно извлечь по запросу aka like 'major1%':
major1/major2/-/minor1/
major1/major3/-/minor1/
major1/major4/-/minor1/
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Доброго времени суток!
В прошлом посте я рассказал о том как извлекать одну запись из NoSQL базы. В случае одной записи все проще простого. А как быть если я хочу вытащить несколько записей? Как сказал бы анатолий Кашперовский, если хочешь вытащить несколько записаей - просто возьми их:)
Итак, перед тем как я буду описывать конкретные реализации инструментов извлечения, хотелось бы рассказать о концепции мультиселекта. Вытаскивать можно ключи с различной вложеностью (можно вытаскивать ключ и его детей, внуков итп...) слева на право, но не наоборот (правила как в прямом префиксном индексе).
Например дано:
major1/major2/-/minor1/
major1/major3/-/minor1/
major1/major4/-/minor1/
major2/major2/-/minor1/
Можно извлечь по запросу aka like 'major1%':
major1/major2/-/minor1/
major1/major3/-/minor1/
major1/major4/-/minor1/
Но нельзя извлечь по запросу aka like '%major2%'.
major1/major2/-/minor1/
major2/major2/-/minor1/
Надеюсь, что не очень запутал, а если запутал,то надеюсь что дальше будет понятнее.
В Oracle NoSQL DB на данный момент существует 3 способа извлечения множество строк.
multiGet() - самый прямолинейный способ извлечени данных фетчит все и сразу в память. Испоьзует структуру SortedMap, данные умеет возвразать в отсортированном порядке. Требует полного major ключа. Приведу пример.
Дано:
major1/major2/-/minor1/
major1/major2/-/minor2/
major1/major3/-/minor1/
Можно извлечь значения ключей (like 'major1/major2%'):
major1/major2/-/minor1/
major1/major2/-/minor2/
Но нельзя (like 'major1/%'):
major1/major2/-/minor1/
major1/major2/-/minor2/
major1/major3/-/minor1/
multiGetIterator() - умеет возвращать данные пачками (если достаем оч. много данных, будет не камельфо, если за одну итерацию в память у нас уйдет терабайт данных). Данные умеет возвращать в отсортированном порядке. Так же как и multiGet() требует полного major key.
storeIterator() - умеет доставать записи пачками. НЕ требуется полного major ключа достаточно куска major key. Сортировать не умеет. Мой неготивный опыт работы с этим оператором - он не возвращает строк по полному major пути. Почему не заню, скорее всего не до разобрался. Впрочем workaround прост - используем для этого multiGet().
Для упрощения своей работы я создал 2 метода: SelectWhere и SelectWhereFullMajor(опять же таки привет моему полу-реляционному мышлению).
public static void SelectWhere(String sKey,KVStore myStore) {
Key myKey = ParseKey.ParseKey(sKey);
try {
Iterator<KeyValueVersion> myrecords =
myStore.storeIterator(Direction.UNORDERED, 0, myKey, null, Depth.PARENT_AND_DESCENDANTS);
while (myrecords.hasNext()) {
Key key = myrecords.next().getKey();
ValueVersion vv = myStore.get(key);
Value v = vv.getValue();
data = new String(v.getValue());
List<String> majorPath1 = key.getMajorPath();
List<String> minorPath1 = key.getMinorPath();
System.out.println(majorPath1 + " - " + minorPath1 + ":" + data);
}
} catch (RequestTimeoutException re) {
System.out.println(re.getTimeoutMs());
} catch (FaultException fe) {
} finally {
}
}
public static void SelectWhereFullMajor(String sKey,KVStore myStore) {
Key myKey = ParseKey.ParseKey(sKey);
try {
// Initialize Matrix
SortedMap<Key, ValueVersion> myrecords = null;
myrecords = myStore.multiGet(myKey, null, Depth.PARENT_AND_DESCENDANTS, Consistency.ABSOLUTE, 1, TimeUnit.DAYS);
for (SortedMap.Entry<Key, ValueVersion> entry : myrecords.entrySet()) {
ValueVersion vv = entry.getValue();
Value v = vv.getValue();
Key myKeyOut = entry.getKey();
String data = new String(v.getValue());
List<String> majorPath1 = myKeyOut.getMajorPath();
List<String> minorPath1 = myKeyOut.getMinorPath();
System.out.println(majorPath1 + " - " + minorPath1 + ":" + data);
}
} catch (RequestTimeoutException re) {
System.out.println(re.getTimeoutMs());
} catch (FaultException fe) {
} finally {
}
}
при описании метода мы определяем глубину чтения (только указанные ключи, ключи и дети...)
Пост 6. CRUD. Retrieve.
Доброго времени суток!
Итак едем дальше! Записывать данные в базу мы воде бы как научились. Теперь хочется научиться читать данные из нее. Ну что же это проще простого:)
Начнем с простого получения одной записи. Используя уже созданные пакеты пишем что то вроде того(прости те мое RDBMS-овское прошлое, не смог удержаться от select =) ):
import java.util.ArrayList;
import java.util.Iterator;
import java.util.List;
import java.util.SortedMap;
import java.util.concurrent.TimeUnit;
import oracle.kv.*;
public class RetrieveNoConnect {
public static String SelectRow(String sKey, KVStore myStore) {
data = null;
Key myKey = ParseKey.ParseKey(sKey);
try {
ValueVersion vv = myStore.get(myKey);
Value v = vv.getValue();
data = new String(v.getValue());
} catch (RequestTimeoutException re) {
System.out.println(re.getTimeoutMs());
} catch (FaultException fe) {
System.out.println("Unknown error");
} catch (NullPointerException ne) {
System.out.println("Key does not exist");
} finally {
}
return data;
}
}
Тут комментировать впринципе нечего, но я все же прокомментирую:) Простите уж меня за тофтологию. Итак, сначала мы получаем на вход строчку sKey, по которой хотим получить запись, преобразуем ее в тип Key (тип NoSQL DB). Далее получаем переменную ValueVersion (собственно само значение и его версию). Затем берем только то, что нам надо в данной конктетной ситуации - значение. Результат возвращаем. Вот впринципе и все. В завершении main:
import java.io.FileNotFoundException;
import java.io.IOException;
import oracle.kv.KVStore;
import simpleoperation.*;
public class TestClass{
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String[] args) throws FileNotFoundException, IOException, InterruptedException {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
System.out.print(simpleoperation.RetrieveNoConnect.SelectRow("major1/major2/-/minor1/",myStore));
myStore.close();
}
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
пятница, 1 июня 2012 г.
Пост 5. CRUD.CREATE. BULK INSERT.
Доброго времени суток!
Продолжаем наше знакомство с Oracle NoSQL Database. В предыдущей статье мы рассматривали операции создания записей в базе. А что на счет массовой загрузки? Строго говоря ее нет. Но очень хотелось бы иметь возможность загружать данные из фала (начальное формирование базы, миграция с другой платформы). Нет проблем! Давайте напишем свой метод с маджонгом и гейшами!
Для начала надо договорить о формате входных данных. Пусть это будет, что то вроде:
major1/major2/-/minor1/minor2/: value
Единственное что стоит заметить (а вы надеюсь это уже заметили), тип value в данном примере только String.
Для начала дополним класс ParseKey методом:
public static Value ParseValue(String keysString) {
String data = keysString.substring(keysString.indexOf(":") + 1);
Value myValue = Value.createValue(data.getBytes());
return myValue;
}
Отлично! Ну и дополняем класс CreateNoConnect методом згрузки из файла:
public static void LoadFromCSV(String filepath, KVStore myStore)
throws FileNotFoundException, IOException {
List<String> majorPath = new ArrayList<>();
List<String> minorPath = new ArrayList<>();
FileReader fr = new FileReader(filepath);
BufferedReader br = new BufferedReader(fr);
String s;
while ((s = br.readLine()) != null) {
Key myKey = ParseKey.ParseKey(s);
Value myValue = ParseKey.ParseValue(s);
myStore.put(myKey, myValue);
majorPath.removeAll(majorPath);
minorPath.removeAll(minorPath);
}
fr.close();
}
public static void LoadFromCSV(String filepath, KVStore myStore)
throws FileNotFoundException, IOException {
List<String> majorPath = new ArrayList<>();
List<String> minorPath = new ArrayList<>();
FileReader fr = new FileReader(filepath);
BufferedReader br = new BufferedReader(fr);
String s;
while ((s = br.readLine()) != null) {
Key myKey = ParseKey.ParseKey(s);
Value myValue = ParseKey.ParseValue(s);
myStore.put(myKey, myValue);
majorPath.removeAll(majorPath);
minorPath.removeAll(minorPath);
}
fr.close();
}
Осталось только сформировать файл входных данных и выполнить main:
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String[] args) throws FileNotFoundException, IOException, InterruptedException {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
simpleoperation.CreateNoConnect.LoadFromFile("C:\\temp\\1.csv", myStore);
myStore.close();
}
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
четверг, 31 мая 2012 г.
Пост 4. CRUD.CREATE.Начинаем работу с Oracle NoSQL DB.
Пока что хватит теории. Давайте немного попрактикуемся. Oracle NoSQL DB поддерживает CRUD (создать, получить, изменить, удалить) операции (позволю себе отвлечься, лучшего ответа на вопрос,что такое база данных я не видел). Итак, хорошие новости! Для того что бы начать работать с NoSQL базой, нам не потребуется много усилий, затраченых на установку оной. Просто качаем небольшой дистрибутив и запускаем версию light. Распаковываем архив, заходим в папочку в случае винды создаем bat файл со следующим содержанием:
java -jar D:\Distr\Linux\NoSQL\kv-2.0.23\lib\kvstore-2.0.23.jar kvlite
и запускаем его. Собственно все, база запущена! У меня под виндами это выглядит как то так:

Теперь нам понадобится какой-либо инструмент для разработки. В моем случае это будет NetBeans (причина выбора оного - личные предпочтения). Итак, база запущена NetBeans открыт, приступим. Прежде чем выполнять какие-либо операции в БД, надо к ней подключится. Делать это мы будем часто, так что давайте создадим отдельный класс, ответственный за это, который будет входить в пакет simpleoperation.
package simpleoperation;
import oracle.kv.KVStore;
import oracle.kv.KVStoreConfig;
import oracle.kv.KVStoreFactory;
public class OraStore {
private final KVStore oraStore;
public OraStore(String sname, String host, String port) {
KVStoreConfig kconfig = new KVStoreConfig(sname, host + ":" + port);
oraStore = KVStoreFactory.getStore(kconfig);
System.out.println("Store Opened");
}
public KVStore getStore() {
return oraStore;
}
}
Как видно для подключения к базе нам потребуется имя хоста, порт базы и имя хранилища(все прям как в RDBMS).
А в главном методе это будет выглядеть как то так:
public class SomeMainClass{
Так подключаться к базе мы умеем. Давайте попробуем создать класс, который будет создавать записи в нашей БД. В документации приведен вот такой вот пример:
package kvstore.basicExample;
import oracle.kv.Key;
import oracle.kv.Value;
import java.util.ArrayList;
...
List<String> majorComponents = new ArrayList<String>();
List<String> minorComponents = new ArrayList<String>();
...
majorComponents.add("Smith");
majorComponents.add("Bob");
minorComponents.add("phonenumber");
Key myKey = Key.createKey(majorComponents, minorComponents);
String data = "408 555 5555";
Value myValue = Value.createValue(data.getBytes());
kvstore.put(myKey, myValue);
Как видно в этом примере мы сначала создаем два массива для major и minor части. Затем заполняем их (в итоге получается: Smith/Bob/-/phonenumber/). Потом объявляем переменную типа String, называем ее value и присваиваем ей какое-нибудь значение, далее в переменную типа Value выдавливаем поток байтов из String (да, кстати, не забудте добавить в библиотеку kvclient-1.2.123.jar). Давайте автоматизируем процесс записи (это действительно сумашествие, каждый раз проделывать такие выкрутасы, для записи одной строки). Для этого:
1) Достигнем неких договоренностей, а именно: ключ будем записывать в виде: major1/major2/-/minor1/minor2/
2) Создадим вспомогательные классы и методы.
Начнем с метода, который парсит строчку в фомат ключа, забивает распаршенное в массив и возвращает переменную типа ключ. Это будет выглядеть как то так:
public static Key ParseKey(String keysString2) {
int endstring;
if (keysString2.indexOf(":") != -1) {
endstring = keysString2.indexOf(":") - 1;
} else {
endstring = keysString2.length();
}
String keysString = keysString2.substring(0, endstring);
List<String> majorComponents = new ArrayList<>();
List<String> minorComponents = new ArrayList<>();
String[] keysArray = keysString.split("/");
boolean isMajor = true;
for (int i = 0; i < keysArray.length; i++) {
if (keysArray[i].equals("-")) {
isMajor = false;
continue;
}
if (isMajor) {
majorComponents.add(keysArray[i]);
} else {
minorComponents.add(keysArray[i]);
}
}
if ((majorComponents.size() > 0) && (minorComponents.size() > 0)) {
myKey = Key.createKey(majorComponents, minorComponents);
} else if ((majorComponents.size() > 0) & (minorComponents.size() <= 0)) {
myKey = Key.createKey(majorComponents);
} else {
System.out.println("Error");
}
return myKey;
}
Отлично! Давайте теперь создадим метод с помощью которого мы можем записать пару ключ-значение:
public static void put(String sKey, String data, KVStore myStore)
throws FileNotFoundException, IOException {
Key myKey = ParseKey.ParseKey(sKey);
Value myValue = Value.createValue(data.getBytes());
myStore.put(myKey, myValue);
}
Понятно, что в этом случае записывать возможно только переменные типа String. Пока остановимся на этом, чуть позже я приведу пример с другими типами данных(фото, видео). Да и обработки исключений здесь нет, все это мы добавим позже (слона как говорится надо есть по частям). В методе mail это будет выглядеть как то так:
public class SomeMainClass{
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Пока что хватит теории. Давайте немного попрактикуемся. Oracle NoSQL DB поддерживает CRUD (создать, получить, изменить, удалить) операции (позволю себе отвлечься, лучшего ответа на вопрос,что такое база данных я не видел). Итак, хорошие новости! Для того что бы начать работать с NoSQL базой, нам не потребуется много усилий, затраченых на установку оной. Просто качаем небольшой дистрибутив и запускаем версию light. Распаковываем архив, заходим в папочку в случае винды создаем bat файл со следующим содержанием:
java -jar D:\Distr\Linux\NoSQL\kv-2.0.23\lib\kvstore-2.0.23.jar kvlite
и запускаем его. Собственно все, база запущена! У меня под виндами это выглядит как то так:

Рис 1. Запуск базы.
package simpleoperation;
import oracle.kv.KVStore;
import oracle.kv.KVStoreConfig;
import oracle.kv.KVStoreFactory;
public class OraStore {
private final KVStore oraStore;
public OraStore(String sname, String host, String port) {
KVStoreConfig kconfig = new KVStoreConfig(sname, host + ":" + port);
oraStore = KVStoreFactory.getStore(kconfig);
System.out.println("Store Opened");
}
public KVStore getStore() {
return oraStore;
}
}
Как видно для подключения к базе нам потребуется имя хоста, порт базы и имя хранилища(все прям как в RDBMS).
А в главном методе это будет выглядеть как то так:
public class SomeMainClass{
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String[] args) throws FileNotFoundException, IOException, InterruptedException {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
...................
...................
myStore.close();
}
}
package kvstore.basicExample;
import oracle.kv.Key;
import oracle.kv.Value;
import java.util.ArrayList;
...
List<String> majorComponents = new ArrayList<String>();
List<String> minorComponents = new ArrayList<String>();
...
majorComponents.add("Smith");
majorComponents.add("Bob");
minorComponents.add("phonenumber");
Key myKey = Key.createKey(majorComponents, minorComponents);
String data = "408 555 5555";
Value myValue = Value.createValue(data.getBytes());
kvstore.put(myKey, myValue);
Как видно в этом примере мы сначала создаем два массива для major и minor части. Затем заполняем их (в итоге получается: Smith/Bob/-/phonenumber/). Потом объявляем переменную типа String, называем ее value и присваиваем ей какое-нибудь значение, далее в переменную типа Value выдавливаем поток байтов из String (да, кстати, не забудте добавить в библиотеку kvclient-1.2.123.jar). Давайте автоматизируем процесс записи (это действительно сумашествие, каждый раз проделывать такие выкрутасы, для записи одной строки). Для этого:
1) Достигнем неких договоренностей, а именно: ключ будем записывать в виде: major1/major2/-/minor1/minor2/
2) Создадим вспомогательные классы и методы.
Начнем с метода, который парсит строчку в фомат ключа, забивает распаршенное в массив и возвращает переменную типа ключ. Это будет выглядеть как то так:
public static Key ParseKey(String keysString2) {
int endstring;
if (keysString2.indexOf(":") != -1) {
endstring = keysString2.indexOf(":") - 1;
} else {
endstring = keysString2.length();
}
String keysString = keysString2.substring(0, endstring);
List<String> majorComponents = new ArrayList<>();
List<String> minorComponents = new ArrayList<>();
String[] keysArray = keysString.split("/");
boolean isMajor = true;
for (int i = 0; i < keysArray.length; i++) {
if (keysArray[i].equals("-")) {
isMajor = false;
continue;
}
if (isMajor) {
majorComponents.add(keysArray[i]);
} else {
minorComponents.add(keysArray[i]);
}
}
if ((majorComponents.size() > 0) && (minorComponents.size() > 0)) {
myKey = Key.createKey(majorComponents, minorComponents);
} else if ((majorComponents.size() > 0) & (minorComponents.size() <= 0)) {
myKey = Key.createKey(majorComponents);
} else {
System.out.println("Error");
}
return myKey;
}
Отлично! Давайте теперь создадим метод с помощью которого мы можем записать пару ключ-значение:
public static void put(String sKey, String data, KVStore myStore)
throws FileNotFoundException, IOException {
Key myKey = ParseKey.ParseKey(sKey);
Value myValue = Value.createValue(data.getBytes());
myStore.put(myKey, myValue);
}
Понятно, что в этом случае записывать возможно только переменные типа String. Пока остановимся на этом, чуть позже я приведу пример с другими типами данных(фото, видео). Да и обработки исключений здесь нет, все это мы добавим позже (слона как говорится надо есть по частям). В методе mail это будет выглядеть как то так:
public class SomeMainClass{
static String port = "5000";
static String host = "localhost";
static String store = "kvstore";
public static void main(String[] args) throws FileNotFoundException, IOException, InterruptedException {
OraStore orastore = new OraStore(store, host, port);
KVStore myStore = orastore.getStore();
SimpleOperations.Create.put("first/key/-/in/db/","Oracle",myStore);
SimpleOperations.Create.put("first/key/-/in/db/","Oracle",myStore);
myStore.close();
}
}
В завершении поста хотел бы заметить, что помимо метода put поддерживаются еще 3 схожих метода. putIfAbsent запишет пару только в случае отсутствия подобного ключа в базе, putIfPresent запишет только если указанный ключ существует(аналог update) и,наконец, putIfVersion запишет, если версия пары эквивалентна указанной. Про версии мы поговорим немного позже!
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
вторник, 29 мая 2012 г.
Пост 3. Архитектура Oracle NoSQL Database.
Доброго времени суток!
В данной статье хотел бы рассказать об архитектуре Oracle NoSQL Database. Oracle NoSQL DB - кластерная база данных (информация хранится на множестве серверов, распределена по принципу партишенинга). Данные задублированы на нескольких серверах (количество копий называется Replication factor). Сервера содержащие одинаковые данные объединяются в Replication Groups (Shard). Внутри шарда реализована мастер-слейв репликация (пишет один, читают со всех). Если Мастер умирает - кто то из слейвов становится мастером (подробнее про master - slave репликацию можно посмотреть здесь). Чем больше мастеров(читай shard-ов) - тем быстрее система работает на запись.

Рис. 1. Пример топологии NoSQL базы.
Минимальная еденица данной системы - Storage Node (применительно к картинке выше - один из девяти серверов). Каждый Storage Node состоит из партиций (помните в самой первой статье говорилось, что на высшем уровне абстракции можно понимать Oracle NoSQL DB как одну огомную таблицу,на самом деле сегментируемую по хэшу от ключа на несколько частей). Секционирование - способ разделения инормации на независимые сегменты. Каждая секция имеет локальный B-Tree индекс. Соответственно, если у нас будет мало секций мы получим большие локальные индексы, а как известно чем больше индекс, тем выше стоимость добавления нового элемента.
Если секций будет очень много - мы получим высокую стоимость накладных расходов на вычисление нужной секции. В общем надо искать компромисс.

Строго говоря, Storage Node - логическая еденица(процесс в ОС), то есть один сервер может включать в себя несколько Storage Node. К примеру, если у нас есть 3 сервера и мы хотим обеспечить 3 репликацию данных - без проблем. Это будет выглядеть как то так:

Доброго времени суток!

Рис. 1. Пример топологии NoSQL базы.
Минимальная еденица данной системы - Storage Node (применительно к картинке выше - один из девяти серверов). Каждый Storage Node состоит из партиций (помните в самой первой статье говорилось, что на высшем уровне абстракции можно понимать Oracle NoSQL DB как одну огомную таблицу,на самом деле сегментируемую по хэшу от ключа на несколько частей). Секционирование - способ разделения инормации на независимые сегменты. Каждая секция имеет локальный B-Tree индекс. Соответственно, если у нас будет мало секций мы получим большие локальные индексы, а как известно чем больше индекс, тем выше стоимость добавления нового элемента.
Если секций будет очень много - мы получим высокую стоимость накладных расходов на вычисление нужной секции. В общем надо искать компромисс.

Рис.2. Key - Value Store в реляционном мышлении.
Строго говоря, Storage Node - логическая еденица(процесс в ОС), то есть один сервер может включать в себя несколько Storage Node. К примеру, если у нас есть 3 сервера и мы хотим обеспечить 3 репликацию данных - без проблем. Это будет выглядеть как то так:

Рис 3. Пример топологии NoSQL базы.
Но все же не рекомендуется держать всю базу на одном очень мощном сервере. Идея NoSQL баз в разнесении хранилища на множество дешевых серверов.
Это касаемо топологии хранилища. Теперь хотелось бы сделать одно маленькое, но весьма значительное замечание по поводу ключа. Ключ состоит из 2х частей major и minor (пример: /Smith/Bob/-/foto/, /Smith/Bob - это major составляющая ключа, а /foto/ - minor). Major part + Minor part = Key. Minor составляющей может и не быть. Major составляющая влияет на распределение ключа по партициям (и как следствие по серверам), minor - просто вспомогательная составляющая.
Пример:
Key: /Mijatovic/foto/ Value: здесь будет аватар
Key: /Mijatovic/foto/-/album1/My_dog Value: здесь будет фотография собаки
Key: /Mijatovic/foto/-/album1/My_Саt Value: здесь будет фотография кошки
В первом примере Minor составляющая отсутствует. У всех трех записей одинаковый Major key => все записи попадут в одну партицию (ну и конечно же в одну репликационную группу).
Key: /Mijatovic/foto/ Value: здесь будет аватар
Key: /Mijatovic/foto/album1/ - /My_dog Value: здесь будет фотография собаки
Key: /Mijatovic/foto/album1/ - /My_Саt Value: здесь будет фотография кошки
В этом случае Major key у второй и третей записи будет отличаться от первой. Скорее всего 1 запись попадет в партицию отличную от партиции 2 и 3 записи. Вот как то так...
Если у вас есть какие-либо вопросы по Oracle NoSQL - задавайте в комментах, постараюсь ответить, либо пишите на oracle.nosql@gmail.com.
Продолжение следует!
четверг, 24 мая 2012 г.
Пост 2. Oracle NoSQL DB основные понятия.
Доброго времени суток!
Как и обещал продолжаю свой блог, посвященный продукту Oracle NoSQL.
Это NoSQL база данных типа ключ-значение. Ключ - это указатель на некий набор байт (value).
Как можно понимать ключ? Давайте возьмем пример прямо из документации этого продукта:
/Mijatovic/address/
/Mijatovic/Phone/
/Mijatovic/Phone/-/Mobile/MTS/
/Mijatovic/Phone/-/Mobile/BeeLine/
/Mijatovic/Phone/-/Work/
Ключ представлен как путь в файловой системе. Признаюсь честно, когда я только начал погружаться в мир NoSQL у меня было ошибочное представление о том, что ключ это нечто монолитное и негибкое. От этого у меня сложилось неверное представление о том, как можно выбирать значения по ключу (от чего я хочу застраховать читателя)... К примеру, когда у меня стояла задача обеспечить хранение и доступ к данным весьма подходящим для концепции key-value, я никак не мог понять что же мне использовать как ключ: идентификатор пользователя, либо UNIX-time события. Правильный ответ:и то и то (/UserId/13800....).
Так же можно понимать ключ в виде иерархического дерева(отдаленно напоминает глобал), как то так:

Важно: в приведенном примере система имеет 5 пар ключ-значение. То есть каждый ключ указанный выше имеет значение, например:
Key: /Mijatovic/address/ Value: г.Москва
Key: /Mijatovic/Phone/ Value: с кнопочками, чёренький :)
Key: /Mijatovic/Phone/-/Mobile/MTS/ Value +7985....
Key: /Mijatovic/Phone/-/Mobile/BeeLine/ Value: +7909....
Key: /Mijatovic/Phone/-/Work/ Value: +7495...
Так же стоит заметить, что у некоторых ключей может не существовать явного "предка" (ключа /Mijatovic/Phone/-/Mobile/ нет). В Oracle NoSQL ключ - всегда string.
А что же такое Value? Тут еще проще - набор байт. Вот уж действительно не отнять не прибавить.
На языке Java это будет как то вот так:
String data = "Тут какой-то текст, может XML-ка, может еще какой-то текст...";
Value myValue = Value.createValue(data.getBytes());
Вашей базе абсолютно все - равно что вы храните в value, никаких типов просто напросто нет. Вы удивитесь и спросите почему, это же шаг назад(а то и несколько шагов)? Ответ прост. Идея NoSQL: чем проще система, тем она быстрее. И действительно мы живем в реальном мире и не можем прыгнуть выше возможностей этого мира (например, позицонирование головки диска ~ 5 мкс, последовательное чтение 100 мб/сек). Каждый функциональные "наворот" все дальше и дальше отдаляет нас от заветных 15 мкс. Хотите накрученную систему блокировок - получите, а вместе с тем и скорость произвольного чтения 100 мкс, вместо 15. Хотите парсер запросов + крутой оптимизатор? Пожалуйста, получите и вместе с тем 200 мкс, вместо 15...

Вот скажите зачем все это системе, которая использует как правило запросы типа дай строчку по первичному ключу(см.ниже)?
select id from tab1 where PrimaryKey= :v1
Вот именно, незачем. Простой системе простая архитектура хранилки. Реляционные базы конечно же более универсальны, но за универсальность приходится платить скоростью. Если Вам нужен одна-две фичи из сотен которые предоставляет реляционка - реализуйте ее на уровне приложения (ну например, определение типа value, что бы для определенных ключей value было бы не просто набором байт, а переменной типа number).
NoSQL, хорошо или плохо?
В конце поста хотел бы привести некоторую аллегорию. Существуют палочки для суши. Созданы они для того что бы есть суши и замечательно для этого подходят. А как быть с супом? Для этого создана ложка, строго говоря, ложкой можно есть все, вопрос на сколько она к этому подходит.
NoSQL не замена реляционным базам (которые жили, живут и будут жить). Это очень узкоспециализированный инструмент, который подходит под некий(достаточно узкий) класс задач.

Доброго времени суток!
Как и обещал продолжаю свой блог, посвященный продукту Oracle NoSQL.
Это NoSQL база данных типа ключ-значение. Ключ - это указатель на некий набор байт (value).
Как можно понимать ключ? Давайте возьмем пример прямо из документации этого продукта:
/Mijatovic/address/
/Mijatovic/Phone/
/Mijatovic/Phone/-/Mobile/MTS/
/Mijatovic/Phone/-/Mobile/BeeLine/
/Mijatovic/Phone/-/Work/
Ключ представлен как путь в файловой системе. Признаюсь честно, когда я только начал погружаться в мир NoSQL у меня было ошибочное представление о том, что ключ это нечто монолитное и негибкое. От этого у меня сложилось неверное представление о том, как можно выбирать значения по ключу (от чего я хочу застраховать читателя)... К примеру, когда у меня стояла задача обеспечить хранение и доступ к данным весьма подходящим для концепции key-value, я никак не мог понять что же мне использовать как ключ: идентификатор пользователя, либо UNIX-time события. Правильный ответ:и то и то (/UserId/13800....).
Так же можно понимать ключ в виде иерархического дерева(отдаленно напоминает глобал), как то так:

Рис 1. Понимание ключа
Важно: в приведенном примере система имеет 5 пар ключ-значение. То есть каждый ключ указанный выше имеет значение, например:
Key: /Mijatovic/address/ Value: г.Москва
Key: /Mijatovic/Phone/ Value: с кнопочками, чёренький :)
Key: /Mijatovic/Phone/-/Mobile/MTS/ Value +7985....
Key: /Mijatovic/Phone/-/Mobile/BeeLine/ Value: +7909....
Key: /Mijatovic/Phone/-/Work/ Value: +7495...
Так же стоит заметить, что у некоторых ключей может не существовать явного "предка" (ключа /Mijatovic/Phone/-/Mobile/ нет). В Oracle NoSQL ключ - всегда string.
А что же такое Value? Тут еще проще - набор байт. Вот уж действительно не отнять не прибавить.
На языке Java это будет как то вот так:
String data = "Тут какой-то текст, может XML-ка, может еще какой-то текст...";
Value myValue = Value.createValue(data.getBytes());
Вашей базе абсолютно все - равно что вы храните в value, никаких типов просто напросто нет. Вы удивитесь и спросите почему, это же шаг назад(а то и несколько шагов)? Ответ прост. Идея NoSQL: чем проще система, тем она быстрее. И действительно мы живем в реальном мире и не можем прыгнуть выше возможностей этого мира (например, позицонирование головки диска ~ 5 мкс, последовательное чтение 100 мб/сек). Каждый функциональные "наворот" все дальше и дальше отдаляет нас от заветных 15 мкс. Хотите накрученную систему блокировок - получите, а вместе с тем и скорость произвольного чтения 100 мкс, вместо 15. Хотите парсер запросов + крутой оптимизатор? Пожалуйста, получите и вместе с тем 200 мкс, вместо 15...

Рис.2. Чем сложнее, тем медленнее
select id from tab1 where PrimaryKey= :v1
Вот именно, незачем. Простой системе простая архитектура хранилки. Реляционные базы конечно же более универсальны, но за универсальность приходится платить скоростью. Если Вам нужен одна-две фичи из сотен которые предоставляет реляционка - реализуйте ее на уровне приложения (ну например, определение типа value, что бы для определенных ключей value было бы не просто набором байт, а переменной типа number).
NoSQL, хорошо или плохо?
В конце поста хотел бы привести некоторую аллегорию. Существуют палочки для суши. Созданы они для того что бы есть суши и замечательно для этого подходят. А как быть с супом? Для этого создана ложка, строго говоря, ложкой можно есть все, вопрос на сколько она к этому подходит.
NoSQL не замена реляционным базам (которые жили, живут и будут жить). Это очень узкоспециализированный инструмент, который подходит под некий(достаточно узкий) класс задач.

Рис.3. Oracle NoSQL DB - очень узкоспециализированный инструмент.
пятница, 18 мая 2012 г.
Пост 1. NoSQL вводная.
Доброго времени суток!
Доброго времени суток!
Этим постом хотел бы открыть серию посвященную новому продукту компании Oracle : Oracle NoSQL Database.
Сперва хотел бы внести свои 5 копеек про NoSQL.
В моем понимании это новое семейство баз данных, которое ориентирована на быструю работу с большим объемом данных и экстремальным колличеством пользователей, расплатой за это становится функционал(ни join, ни count...). Произошло движение от сложного к простому. И действительно чем сложнее система, тем она медленнее, чем больше наворотов, тем дальше мы от возможностей физического мира (случайное чтение ~ 15 мкс, последовательное чтение ~ 100 Мб/c), добавляя все новый и новый слой функционала мы отдаляемся от заветных 15 мкс...
Спорить о том "хорошо или плохо NoSQL" я не хочу. Для каждой задачи есть свой инструмент, многие вещи (за исключением проектов крупных интернет гигантов типа Google, facebook...) можно было то сделать и на привычных реляционных БД, но тут встает вопрос что проще и целесообразнее? Возьмем к примеру палочки для суши, ими замечательно можно есть суши! А суп? А пиццу? Наверно не очень удобно :) С другой стороны есть столовая ложка, которой при некой доле снаровки можно съесть все что угодно (и суши и суп), только в некоторых случаях это будет с большое долей извращения. Это сугубо мое личное мнение и мое видение технологии, которое не претендует на истину в последней инстанции.
Мне вспоминается всем известный стишок из всеми любимого фильма "...по миру идет не спеша хорошая девочка Лида. Да чем же она хороша?", так чем же хороши эти базы данных?
Для начала стоит оговориться, что среди NoSQL выделяют 4 типа:
Сперва хотел бы внести свои 5 копеек про NoSQL.
В моем понимании это новое семейство баз данных, которое ориентирована на быструю работу с большим объемом данных и экстремальным колличеством пользователей, расплатой за это становится функционал(ни join, ни count...). Произошло движение от сложного к простому. И действительно чем сложнее система, тем она медленнее, чем больше наворотов, тем дальше мы от возможностей физического мира (случайное чтение ~ 15 мкс, последовательное чтение ~ 100 Мб/c), добавляя все новый и новый слой функционала мы отдаляемся от заветных 15 мкс...
Спорить о том "хорошо или плохо NoSQL" я не хочу. Для каждой задачи есть свой инструмент, многие вещи (за исключением проектов крупных интернет гигантов типа Google, facebook...) можно было то сделать и на привычных реляционных БД, но тут встает вопрос что проще и целесообразнее? Возьмем к примеру палочки для суши, ими замечательно можно есть суши! А суп? А пиццу? Наверно не очень удобно :) С другой стороны есть столовая ложка, которой при некой доле снаровки можно съесть все что угодно (и суши и суп), только в некоторых случаях это будет с большое долей извращения. Это сугубо мое личное мнение и мое видение технологии, которое не претендует на истину в последней инстанции.
Мне вспоминается всем известный стишок из всеми любимого фильма "...по миру идет не спеша хорошая девочка Лида. Да чем же она хороша?", так чем же хороши эти базы данных?
Для начала стоит оговориться, что среди NoSQL выделяют 4 типа:
1) Key - value
2) Column famaly
3) Документоориентированные
4) Графориентированные
2) Column famaly
3) Документоориентированные
4) Графориентированные
Подробнее вот тут
Я остановлюсь на БД типа ключ - значение (Key - value). В основу этого подхода положено то, что все данные разбиваются на пары ключ -значения, где ключ - это просто индекс, а значение набор байтов, расшифровывать которое будет приложение.
В реляционном мире это выглядело бы вот так:
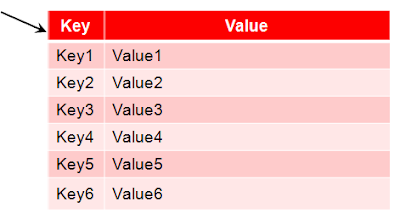
Рис 1. Представление Key - Value в реляционном мышлении
Я остановлюсь на БД типа ключ - значение (Key - value). В основу этого подхода положено то, что все данные разбиваются на пары ключ -значения, где ключ - это просто индекс, а значение набор байтов, расшифровывать которое будет приложение.
В реляционном мире это выглядело бы вот так:

Рис 1. Представление Key - Value в реляционном мышлении
Так все-таки где могут быть полезны такие БД? В первую очередь для хранения неструктурированной информации или полуструктурированной (фото, XML, JSON...). Для получения быстрого отклика на простые запросы (дай значение по ключу). Для хранения большого объема данных (терабайты, петабайты...). Для поддержания большого количества одновременно работающих пользователей. Ну и впринципе везде где использование реляционок не целесообразно (если не использутеся 99% функционала, а тот 1 процент есть в NoSQL альтернативе).
Постараюсь привести ряд примеров:
• Facebook
Почему? Данных очень много
• Google
Почему? Данных очень много
• Twitter
Почему? Данных очень много
Постараюсь привести ряд примеров:
Почему? Данных очень много
Почему? Данных очень много
Почему? Данных очень много
Ну а если у меня нет ни гугла, ни твитера, ни фейсбука? :)
Тогда:
• LDAP подобные системы - простой ответ на простой вопрос
Почему? Это быстро!
• Хранилище USSD запросов мобильных пользователей
Почему? Нет четкой структуры исходных данных
• Персоонализация пользователей
Почему? Нет четкой стрктуры данных, постоянные доработки системы
• Сбор разнотипных данных со счетчиков
Почему? Требуется поддержка большого колличества одновременных сессий
• Логирование интернет трафика (CDR GPRS, web logs)
Почему? Данных очень много
• Хранилище файлов (фотографии, видео, текст)
Почему? Данных может быть очень много и к ним требуется быстрый доступ (системы аналогичные drop box, Google disk)
• Интернет магазины
Почему? Нет четкой структуры данных. Данных может быть много
• Антиспам системы
Почему? Очень много простых запросов (пример: Mollom)
Вот наверное и все что я хотел сказать про NoSQL.
В следующем посте будет рассмотрен конкретный продукт - Oracle NoSQL
Тогда:
• LDAP подобные системы - простой ответ на простой вопрос
Почему? Это быстро!
• Хранилище USSD запросов мобильных пользователей
Почему? Нет четкой структуры исходных данных
• Персоонализация пользователей
Почему? Нет четкой стрктуры данных, постоянные доработки системы
• Сбор разнотипных данных со счетчиков
Почему? Требуется поддержка большого колличества одновременных сессий
• Логирование интернет трафика (CDR GPRS, web logs)
Почему? Данных очень много
• Хранилище файлов (фотографии, видео, текст)
Почему? Данных может быть очень много и к ним требуется быстрый доступ (системы аналогичные drop box, Google disk)
• Интернет магазины
Почему? Нет четкой структуры данных. Данных может быть много
• Антиспам системы
Почему? Очень много простых запросов (пример: Mollom)
Вот наверное и все что я хотел сказать про NoSQL.
В следующем посте будет рассмотрен конкретный продукт - Oracle NoSQL
Подписаться на:
Комментарии (Atom)